# DAN: a Segmentation-free Document Attention Network for Handwritten Document Recognition
This repository is a public implementation of the paper: "DAN: a Segmentation-free Document Attention Network for Handwritten Document Recognition".
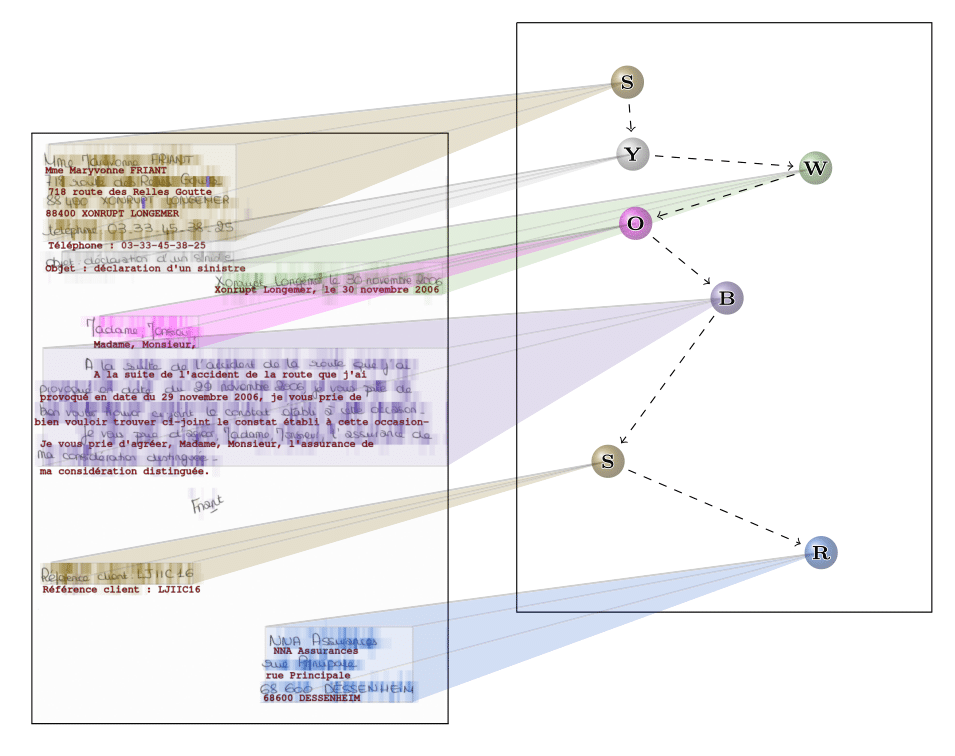
The model uses a character-level attention to handle slanted lines:

The paper is available at https://arxiv.org/abs/2203.12273.
To discover my other works, here is my [academic page](https://factodeeplearning.github.io/).
Click to see the demo:
[](https://www.youtube.com/watch?v=HrrUsQfW66E)
This work focus on handwritten text and layout recognition through the use of an end-to-end segmentation-free attention-based network.
We evaluate the DAN on two public datasets: RIMES and READ 2016 at single-page and double-page levels.
We obtained the following results:
| | CER (%) | WER (%) | LOER (%) | mAP_cer (%) |
| :---------------------: | ------- | :-----: | :------: | ----------- |
| RIMES (single page) | 4.54 | 11.85 | 3.82 | 93.74 |
| READ 2016 (single page) | 3.53 | 13.33 | 5.94 | 92.57 |
| READ 2016 (double page) | 3.69 | 14.20 | 4.60 | 93.92 |
Pretrained model weights are available [here](https://git.litislab.fr/dcoquenet/dan).
Table of contents:
1. [Getting Started](#Getting-Started)
2. [Datasets](#Datasets)
3. [Training And Evaluation](#Training-and-evaluation)
## Getting Started
We used Python 3.9.1, Pytorch 1.8.2 and CUDA 10.2 for the scripts.
Clone the repository:
```
git clone https://github.com/FactoDeepLearning/DAN.git
```
Install the dependencies:
```
pip install -r requirements.txt
```
### Remarks (for pre-training and training)
All hyperparameters are specified and editable in the training scripts (meaning are in comments).\
Evaluation is performed just after training ending (training is stopped when the maximum elapsed time is reached or after a maximum number of epoch as specified in the training script).\
The outputs files are split into two subfolders: "checkpoints" and "results". \
"checkpoints" contains model weights for the last trained epoch and for the epoch giving the best valid CER. \
"results" contains tensorboard log for loss and metrics as well as text file for used hyperparameters and results of evaluation.
## `Predict` module
This repository also contains a package to run a pre-trained model on an image.
### Installation
To use DAN in your own scripts, install it using pip:
```console
pip install -e .
```
### Usage
To apply DAN to an image, one needs to first add a few imports and to load an image. Note that the image should be in RGB.
```python
import cv2
from dan.predict import DAN
image = cv2.cvtColor(cv2.imread(IMAGE_PATH), cv2.COLOR_BGR2RGB)
```
Then one can initialize and load the trained model with the parameters used during training.
```python
model_path = 'model.pt'
params_path = 'parameters.yml'
charset_path = 'charset.pkl'
model = DAN('cpu')
model.load(model_path, params_path, charset_path, mode="eval")
```
To run the inference on a GPU, one can replace `cpu` by the name of the GPU. In the end, one can run the prediction:
```python
text, confidence_scores = model.predict(image, confidences=True)
```
### Commands
This package provides three subcommands. To get more information about any subcommand, use the `--help` option.
#### Data extraction from Arkindex
Use the `teklia-dan dataset extract` command to extract a dataset from Arkindex. This will generate the images and the labels needed to train a DAN model.
The available arguments are
| Parameter | Description | Type | Default |
| ------------------------------ | ----------------------------------------------------------------------------------- | -------- | ------- |
| `--parent` | UUID of the folder to import from Arkindex. You may specify multiple UUIDs. | `str/uuid` | |
| `--element-type` | Type of the elements to extract. You may specify multiple types. | `str` | |
| `--parent-element-type` | Type of the parent element containing the data. | `str` | `page` |
| `--output` | Folder where the data will be generated. | `Path` | |
| `--load-entities` | Extract text with their entities. Needed for NER tasks. | `bool` | `False` |
| `--tokens` | Mapping between starting tokens and end tokens. Needed for NER tasks. | `Path` | |
| `--use-existing-split` | Use the specified folder IDs for the dataset split. | `bool` | |
| `--train-folder` | ID of the training folder to import from Arkindex. | `uuid` | |
| `--val-folder` | ID of the validation folder to import from Arkindex. | `uuid` | |
| `--test-folder` | ID of the training folder to import from Arkindex. | `uuid` | |
| `--transcription-worker-version` | Filter transcriptions by worker_version. Use ‘manual’ for manual filtering. | `str/uuid` | |
| `--entity-worker-version` | Filter transcriptions entities by worker_version. Use ‘manual’ for manual filtering | `str/uuid` | |
| `--train-prob` | Training set split size | `float` | `0.7` |
| `--val-prob` | Validation set split size | `float` | `0.15` |
The `--tokens` argument expects a file with the following format.
```yaml
---
INTITULE:
start: ⓘ
end: Ⓘ
DATE:
start: ⓓ
end: Ⓓ
COTE_SERIE:
start: ⓢ
end: Ⓢ
ANALYSE_COMPL.:
start: ⓒ
end: Ⓒ
PRECISIONS_SUR_COTE:
start: ⓟ
end: Ⓟ
COTE_ARTICLE:
start: ⓐ
end: Ⓐ
CLASSEMENT:
start: ⓛ
end: Ⓛ
```
To extract HTR+NER data from **pages** from [this folder](https://arkindex.teklia.com/element/665e84ea-bd97-4912-91b0-1f4a844287ff), use the following command:
```shell
teklia-dan dataset extract \
--parent 665e84ea-bd97-4912-91b0-1f4a844287ff \
--element-type page \
--output data \
--load-entities \
--tokens tokens.yml
```
with `tokens.yml` having the content described just above.
To do the same but only use the data from three folders, the commands becomes:
```shell
teklia-dan dataset extract \
--parent 2275529a-1ec5-40ce-a516-42ea7ada858c af9b38b5-5d95-417d-87ec-730537cb1898 6ff44957-0e65-48c5-9d77-a178116405b2 \
--element-type page \
--output data \
--load-entities \
--tokens tokens.yml
```
To use the data from three folders as **training**, **validation** and **testing** dataset respectively, the commands becomes:
```shell
teklia-dan dataset extract \
--use-existing-split \
--train-folder 2275529a-1ec5-40ce-a516-42ea7ada858c
--val-folder af9b38b5-5d95-417d-87ec-730537cb1898 \
--test-folder 6ff44957-0e65-48c5-9d77-a178116405b2 \
--element-type page \
--output data \
--load-entities \
--tokens tokens.yml
```
To extract HTR data from **annotations** and **text_zones** from [this folder](https://demo.arkindex.org/element/48852284-fc02-41bb-9a42-4458e5a51615) that are children of **single_pages**, use the following command:
```shell
teklia-dan dataset extract \
--parent 48852284-fc02-41bb-9a42-4458e5a51615 \
--element-type text_zone annotation \
--parent-element-type single_page \
--output data
```
#### Dataset formatting
Use the `teklia-dan dataset format` command to format a dataset. This will generate two important files to train a DAN model:
- `labels.json`
- `charset.pkl`
The available arguments are
| Parameter | Description | Type | Default |
| ------------------------------ | ----------------------------------------------------------------------------------- | -------- | ------- |
| `--dataset` | Path to the folder containing the dataset. | `str/uuid` | |
| `--image-format` | Format under which the images were generated. | `str` | |
| `--keep-spaces` | Transcriptions are trimmed by default. Use this flag to disable this behaviour. | `str` | |
```shell
teklia-dan dataset format \
--dataset path/to/dataset \
--image-format png
```
The created files will be stored at the root of your dataset.
#### Model training
`teklia-dan train` with multiple arguments.
#### Synthetic data generation
`teklia-dan generate` with multiple arguments